Welcome to
CANDOR
Collecting and Analyzing Networked Data for Open Research
How it works
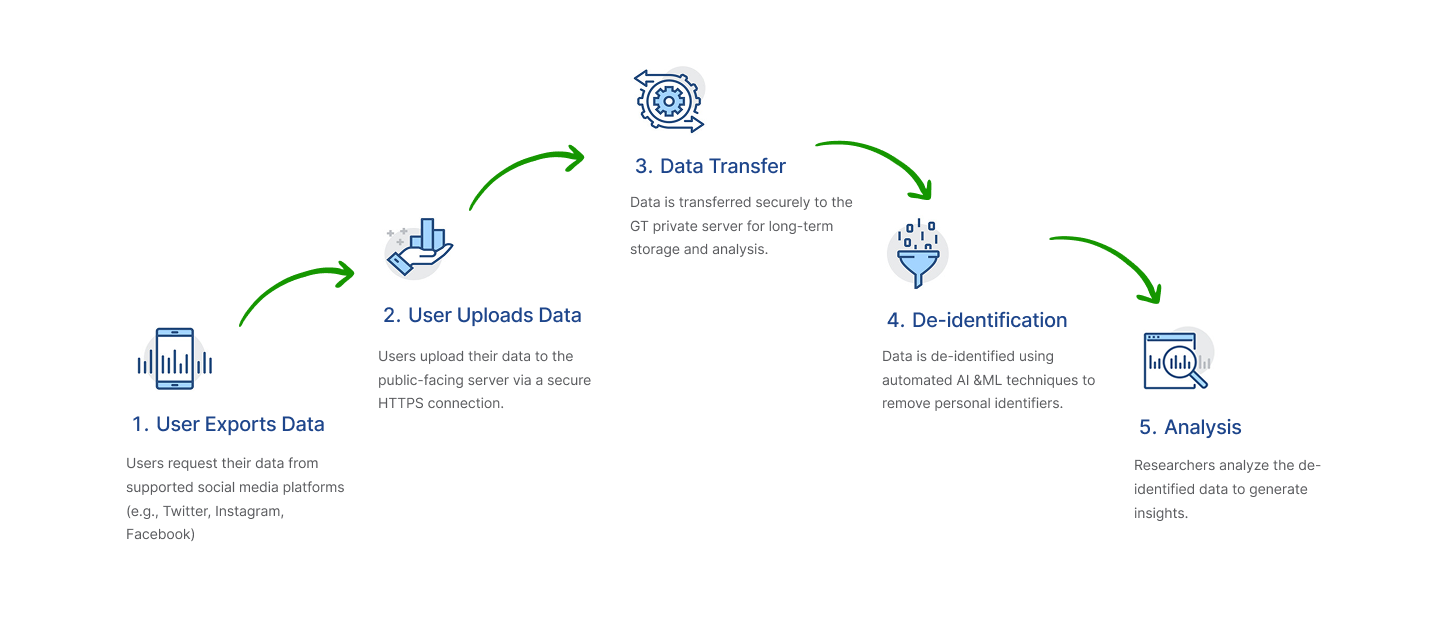
The CANDOR Data Donation Portal is a secure platform designed to collect and analyze social media data for research purposes. Users can upload their data from supported platforms like Twitter, Instagram, and Facebook. The system ensures privacy by de-identifying all data using advanced machine learning techniques. Data is stored and analyzed on Georgia Tech’s secure servers, accessible only to authorized researchers.
Please reach out to your Study Coordinator for a Unique Link to upload your data to.
Exporting Data
By virtue of the GDPR, participants can request archives of their data from almost all major online platforms. Participants will start by requesting data from platforms as dictated by their study coordinator and what they are comfortable sharing. Depending on the platform, it may take from a few minutes to two weeks to receive their participant data. Participants will often receive an email that their upload is ready, but for more platform specific instructions, please see our Export Data page.
See how to export data here.
Uploading Data
After a participant downloads their data from their platform(s) of choice, they connect to this website at the link given to them by their study coordinator. As the data is being uploaded to the participant’s browser, it will be renamed based on their participant ID, study, and type of data. This is done both to label the data uploaded and to remove the participant’s social media handle from the filename. We use a common yet secure mechanism to transfer participant files from the participant’s computer to our server called HTTPS. All sensitive online information sharing from bank transactions to health insurance use this to ensure that data is secure as it travels over the net.
Data Transfer
After we receive the data on our website’s server, we automatically begin transferring it encrypted to a Georgia Tech (GT) internal server for long-term storage. With GT-internal servers, one needs to be on GT’s Wifi or a Virtual Private Network (VPN) to connect which minimizes the exposure of participant data to outside breaches. VPNs are simply a secure, login-enforced way to connect to our school’s network from an outside network, i.e. Home Wifi, with encrypted data transfer. Our internal server only allows authorized lab members and trained IT administrators access to the files with two-factor authentication.
De-identification
After files have been transferred to our internal server, we begin de-identification of a participant’s data. This means that the data will be stripped of identifiers such as names, dates of birth, addresses, phone numbers, emails, social security numbers, and other identifiable features to the extent possible via automated machine learning-based techniques. Data is considered deidentified to the extent possible, because some participants may communicate on social media using nicknames, codenames, or other non-standard references that could be missed by automated deidentification procedures, which could possibly be identifiable. For example, automated deidentification software would recognize and remove references such as "Cinci" or "Philly," referring to a participant living in Cincinnati or Philadelphia. However, it may miss more localized/less well-known references, such as "the Hill" to refer to the Hill District in Pittsburgh. While not perfect, these methods ensure that identifiable information is removed to the best extent possible prior to any researcher touching the data. Furthermore, any processed or analyzed data used in presentations, publications, or public-facing reports will be paraphrased or edited adequately to remove potential risk of traceability to specific participants.
Analysis
We will employ Artificial Intelligence/Machine Learning techniques on the text, images, and social interactions from a participant to infer various characteristics about the participant and their interactions – which can be read in more detail on our data usage page. These may then be used to enhance any clinical interventions participants are involved in and to broadly improve our understanding of the connection between social media and mental health outcomes.
See research data usage here.
This work has been supported through NIH grants R01GM112697, R01MH117172, P50MH115838, R21MH125256, K23MH131759, R01MH135488, a cooperative research agreement from Feinstein Institute of Medical Research, Betty and Gordon Moore Foundation, and the American Foundation for Suicide Prevention (AFSP).

